闲来无事,决定把java大程干了
刚接触Py是因为玩爬虫,最简单的就是获取一些静态网页资源,一句话解决了,好不痛快,甚至有点弱智,后来发现原来网站也有三六九等,一些普通的博客啦,天气网站啦,都傻乎乎的没一点反爬措施,让我错以为所有的网站的都这样,后来被打脸才发现,原来不是这样的,比方知乎就不是一行代码能解决的啦.都说BAT的网站难爬,无数工程师智慧的结晶啊.可到底有多难?我就是要试试水,今天就拿麻花藤开刀.
首先给出引颈受戮的URL 大家可以先行体验一下: 传送门
为什么会去尝试爬这个呢?这里有段渊源:博主曾经利用python 调用过一个叫QQbot 的库,他就是爬取这个URL,首先抓取下来二维码,然后用户扫码之后,信息post回去实现登陆,(其中有很多技术细节,之后会细说)。模拟登陆成功以后就开辟多个线程,都阻塞在等待新消息进入这一状态,当有好友发送消息到该QQ时,对应的WebQQ自然后有从后台发过来的数据包,我们要做的就是抓取下来,然后原本阻塞在等待新消息进入的线程就会重回到就绪队列,可以进行下一步动作.这个Py的库做的就是这么多,它提供的可以说仅仅是一个接口,至于消息进来之后如何区分回复这是要自己去实现的。
这个实现了之后怎么玩呢?
你可以开辟一个线程去抓取天气,与其结合做一个天气问答机器人,也可以做一个简单的智能聊天机器人。但我感兴趣的不是这个,我感兴趣的是其中实现的模拟登陆,以及消息抓取和回复这一整个流程的实现,于是决定利用Java重写这个QQbot,不使用任何第三方库,实际上也没有好的JAVA包可以使用,于是从零开始,重新写了一个Java版的QQ聊天机器人,并把整个项目工程做成了一个Java包,可以供第三方调用。
实现思路
现在在这里大致讲一下我的实现思路,供想深入学习爬虫的人学习。实际上BAT的网页都不好爬取,毕竟大公司,我也写过一个淘宝后台抓取订单,然后调用短信API发送发货提醒短信,花了不少精力,阿里和腾讯的网站都有大量的反扒机制。但是,你如果成功爬取了,你将对爬虫的原理,和爬虫如何应对反扒机制有更深刻的理解,也将对网站现有的反扒机制有一些了解,方便之后你建站时设计这些反扒机制。
实现模拟登陆:
1)获取主页面下的 二维码并保存 在本地 Login.jpg下。
2)不断扫描该二维码的信息,检查其被扫描情况:未被扫描,扫描,过期
->若二维码过期则重复步骤一
->若被扫描,则获取其返回信息,保存其response header中的Set-cookie
获取必要的四个参数:
1)完成扫码之后,需要利用扫码过程中的 Set-cookie组建新的Cookie
2)利用新建的Cookie继续向参数获取URLpost 请求以获得和用户相关的参数
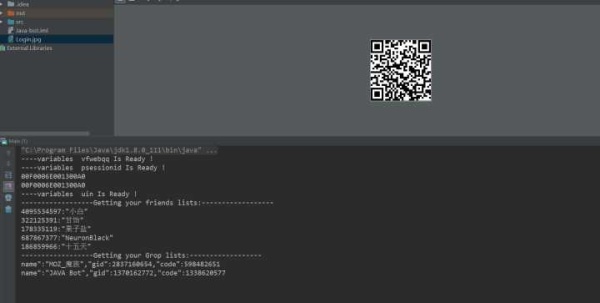
利用获取的参数获得用户的好友信息,群组信息并打印:
1)得到四个参数,抓取信息,向指定URLpost请求,请求参数为四个参数组合得到用户的好友信息以及群组信息。
注意:这里存在不是利用 四个参数直接明码post,会出现另外的参数,实际上该参数是以你获得的四个参数进行特定的加密方式已得到的新的请求参数。这是最难的地方。
找到webqq如何请求检查是否有新信息的请求:
用浏览器登录你的webqq,抓包观察在登陆之后定期或发送的一个请求 ,名字叫做poll2的请求, 以此为例子,构建你自己的请求。然后按照上述所说构建四个线程,以一定的频率去post这个请求以获得不断刷新的效果。
获取信息之后回复信息:
当你的抓取线程抓取到消息时,你会获得发送者的ID以及文本信息,作出处理之后得到回复文本,然后向发送消息的URL构建Post请求,参数为你得到的回复文本以及回复对象ID。
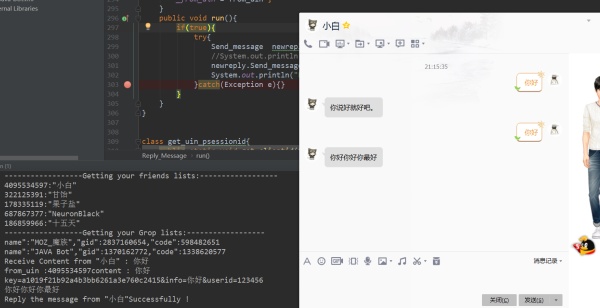
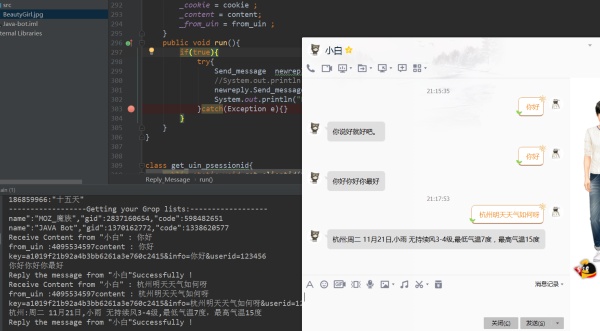
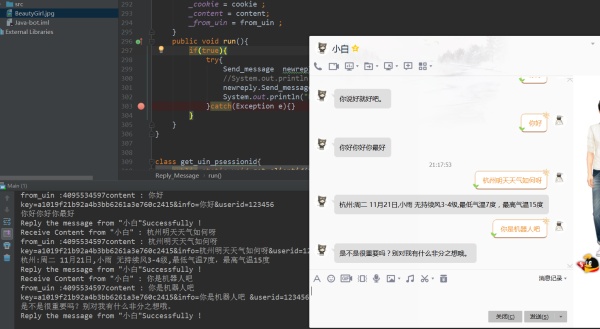
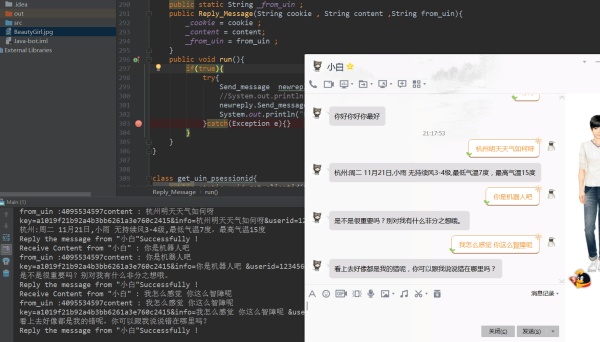
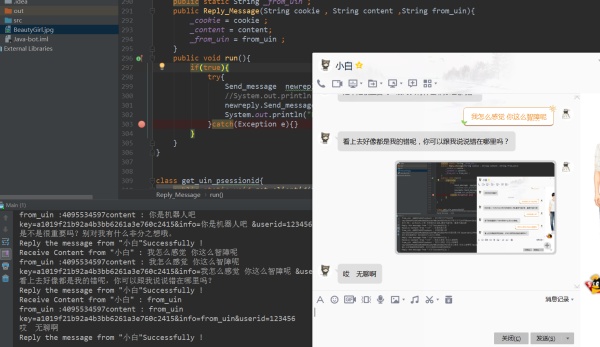
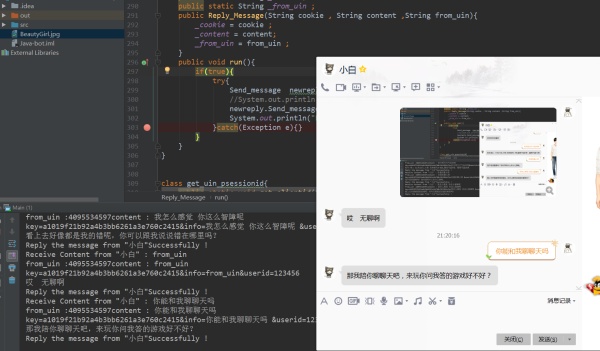
注:回复消息的URL,也利用浏览器发送并且F12抓包获取其格式。
版本 2.0 更新时间:12/17/2:27
GitHub 地址:项目源码传送门
(因为涉及网站的消息爬取,项目源码是一个时效性很高的东西,一旦在我更新期间到您看到这篇文章之间网站做过更改,就有可能无法复现结果,博主最近也无精力维护,见谅)
具体代码在GitHub上已经上传(实测可跑),欢迎大家复现我的结果,因为程序的一些小瑕疵,鼓励使用提供的小号测试,当然GitHub的readme.TXT 当中写的很清楚了,具体的代码实现思路及细节以后会更新。
有任何想法想与我交流欢迎私信我。